I. Challenges Addressed
Large audio-language models (LALMs) face significant challenges:
- Ineffective paralinguistic modeling: Existing solutions struggle to capture intonation, emotion, and vocal states while overemphasizing semantic content
- Severe end-to-end hallucination: Current architectures lack access to real-world textual and acoustic knowledge bases
Step-Audio 2 resolves these through three innovations:
- Genuine end-to-end architecture: Direct raw audio processing enabling effective paralinguistic comprehension
- COT-reinforcement learning fusion: First model with audio reasoning capabilities for precise understanding of non-textual signals
- Acoustic knowledge enhancement: Leverages web search and audio retrieval to eliminate hallucinations while enabling dynamic voice switching
Demos
Hello, I’m Xiao Yue, your intelligent assistant companion.
Companion Mode: Paralinguistic Comprehension
Voice Analysis: Recognition Capabilities
Cognitive Expertise: Learning & Computation
Multilingual Mastery: Dialect Comprehension
Dynamic Voice: Tone Switching
Narrative Generation: Creative Expression
Emotional Intelligence: Dialogue Reasoning
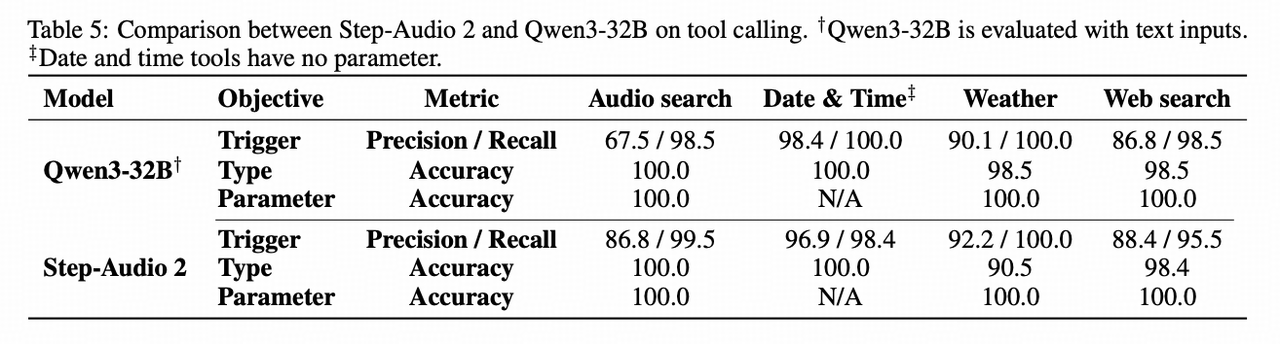
II. Technical Advantages: Innovations and Breakthroughs
Compared to existing solutions, Step-Audio 2 introduces:
2.1 Architecture Innovation
- Genuine end-to-end processing ⇨ Eliminates traditional ASR+LLM+TTS pipelines ⇨ Reduces latency and simplifies architecture
- Continuous input/discrete output paradigm ⇨ Processes raw waveforms to prevent feature loss ⇨ Ensures synthesis stability via discrete acoustic tokens
- Interleaved modality alignment ⇨ Implements fixed-ratio text-speech token interlacing ⇨ Ensures tight modality alignment while maximizing cognitive ceiling
2.2 Data Engineering
- Multi-million hour acoustic corpus ⇨ Training spans languages, scenarios, and device environments
- High-emotion dialogue synthesis pipeline
2.3 Highlights
- Acoustic reasoning capability
⇨ Industry-leading granular comprehension:
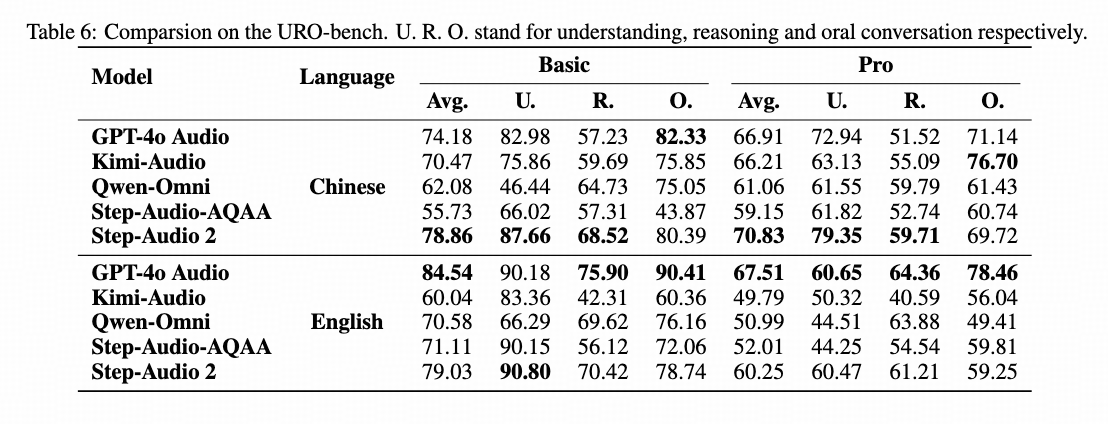
- SOTA 78.86 on Chinese dialogue benchmark (URO-Bench)
- 76.55% accuracy on 11 paralinguistic features (Step-SPQA)
- 77.4% on MMAU benchmark, surpassing GPT-4o-Audio and Gemini-2.5-Pro
- Real-time voice modulation ⇨ Voice-command triggered tone switching
III. Experience Step-Audio 2
You can live interact with Step-Audio 2 in the latest StepFun App, which will be released soon! Open the app and select the microphone icon for live interaction:
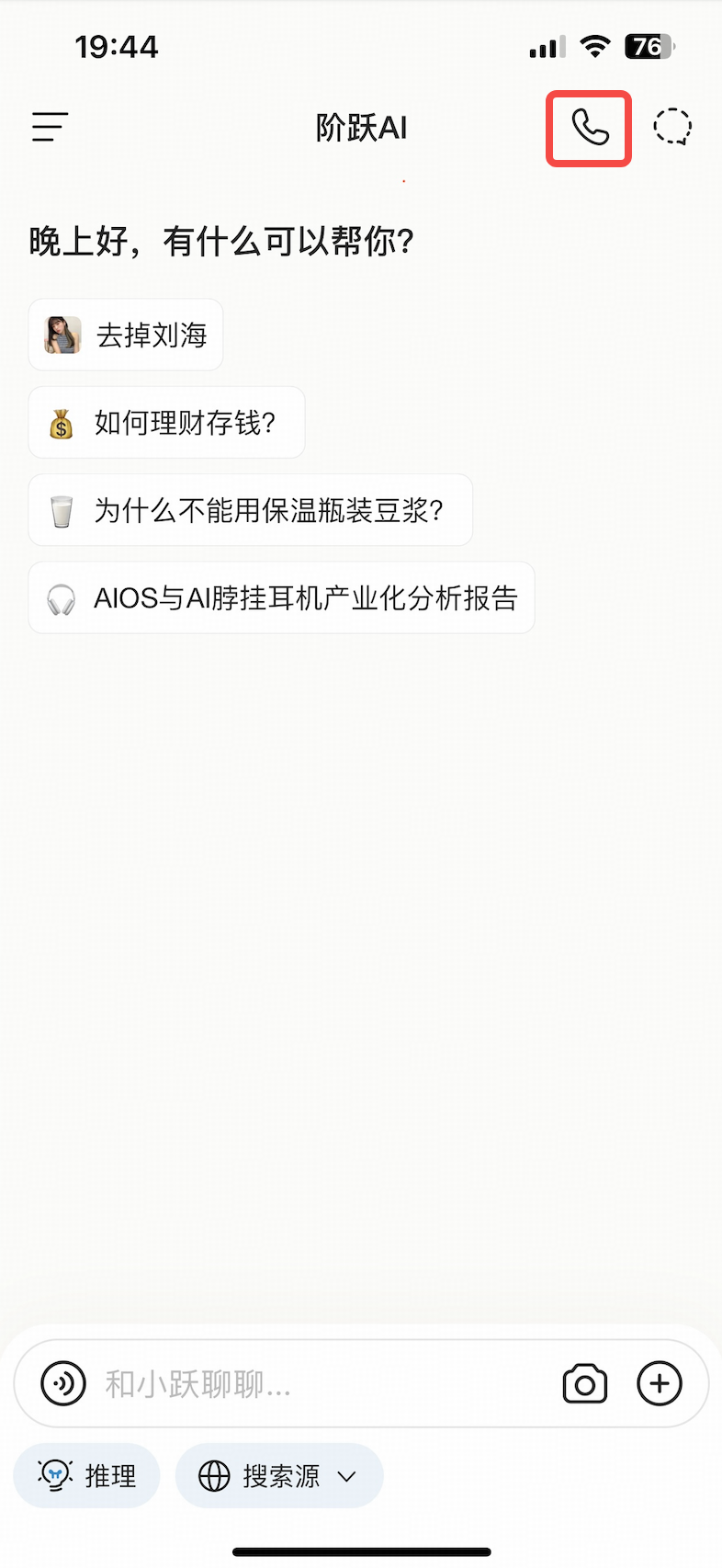
IV. Benchmark Performance
1. Public Leaderboards
-
SOTA on multiple ASR benchmarks:
- English: #1 globally on Common Voice/LibriSpeech, #1 domestically on Fleurs-EN
- Chinese: #1 globally on AISHELL-2/KeSpeech (heavy accent)/WenetSpeech, #1 domestically on Fleurs-zh
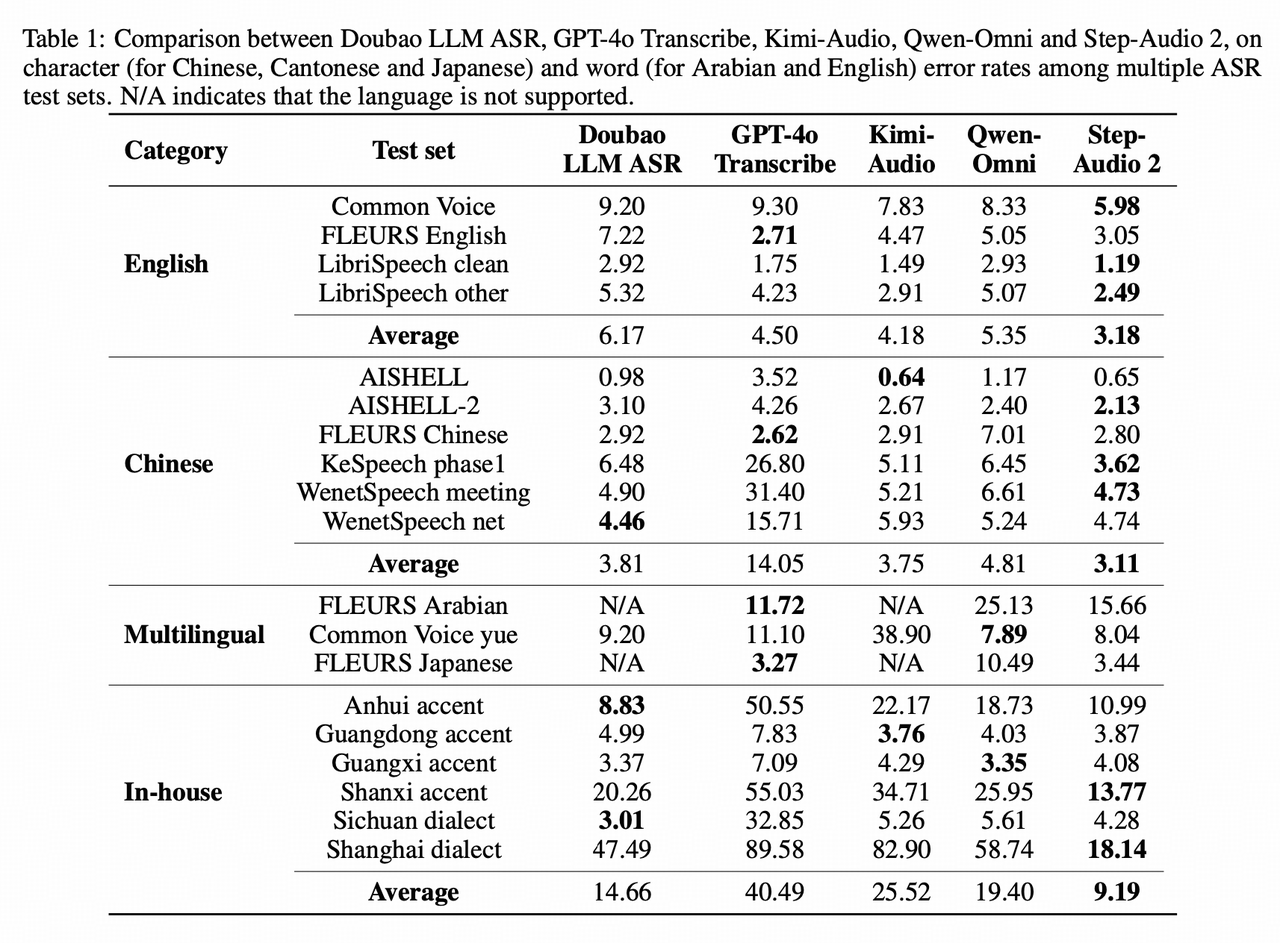
-
MMAU: #1 globally, outperforming GPT-4o-Audio, Gemini-2.5-Pro, NVIDIA’s Audio Flamingo3, and specialist compact models: Omni-R1
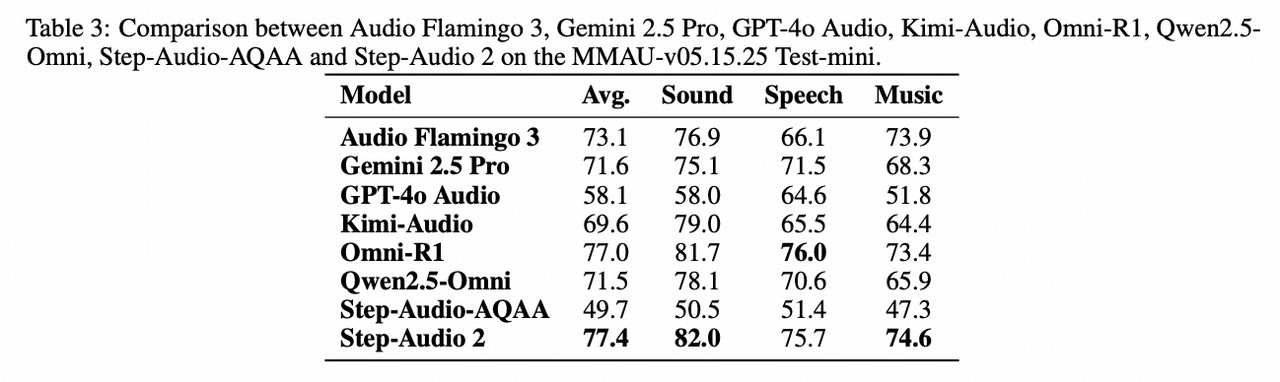
-
URO-Bench: #1 globally for Chinese, #1 domestically for English
2. Self-built Benchmarks
-
Step-SPQA: Industry’s first paralinguistic comprehension benchmark, ranked #1 globally
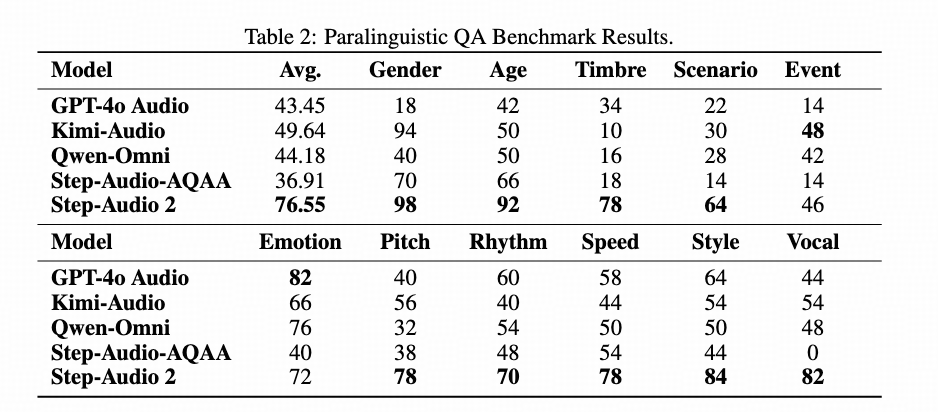
-
Step-AudioToolcall: World’s first voice-enabled toolcall benchmark