
一、为何要深度编辑模型
近期,随着Gemini2.0、GPT-4o、seededit3.0 和 Step 1x-edit 模型的发布,一句话让AI模型进行图像编辑已经成为现实,用户可以一句话改图,包括修图、换装、美化、转化风格、在指定区域添加删除元素等各类编辑操作,通过简单的自然语言即可驱动模型编辑任意图像。 尽管指令式图像编辑模型取得了巨大的进展,复杂场景下的编辑仍然具有挑战性:比如将拍的牛排照片改造成商品宣传海报,这需要对原始图和指令进行思考拆解,形成指令链:「去除杂乱背景,保留主体 → 替换为简洁、高级感或氛围感背景,如深色大理石 → 调整颜色、饱和度、对比度让牛排更有质感 → 加入宣传文案,如“Bold Juicy”」


二、深度编辑模型是如何炼成的
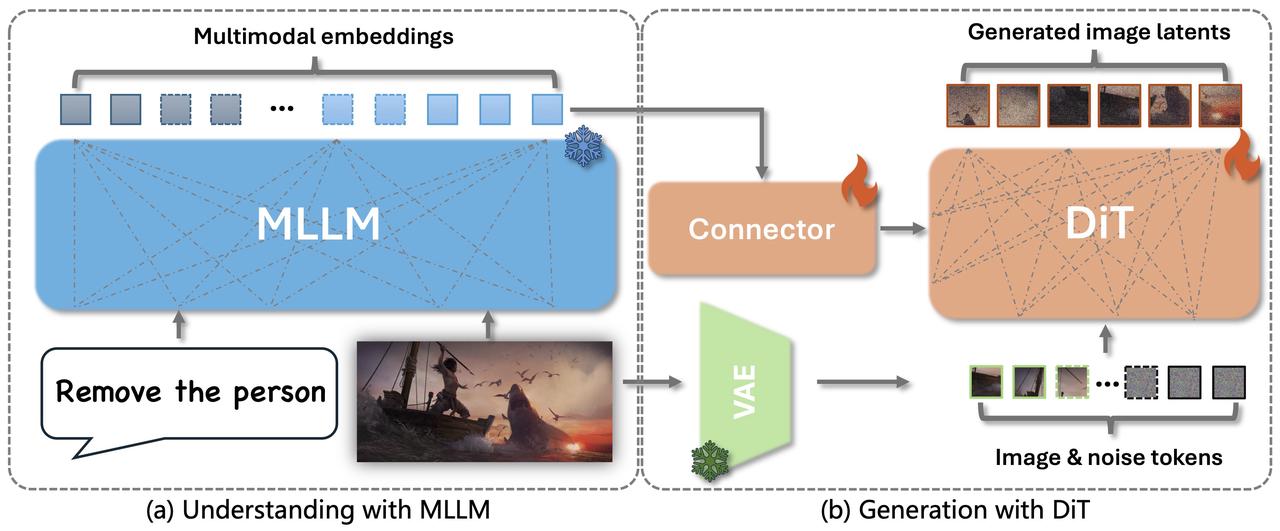
基于上述分析,我们提出了深度编辑模型(Deep Edit Model),这是一种“think with image”范式的智能图像编辑系统。其核心理念是将多模态视觉推理能力引入复杂图像编辑任务中,构建一个“推理–编辑–反思”闭环链路,模拟人类设计师在解决高阶编辑问题时的思维与创作过程。该模型由 Step1x-edit 基础模型训练得到,其架构包含以下关键组件:
1.多模态理解模块(Multimodal Perception Module),该模块能够同时接收图像和文本输入,实现对原始图像的上下文理解与用户编辑意图的融合。图像输入提供原始图像内容作为条件,保留视觉上下文,确保编辑的针对性和局部一致性;文本输入接收用户的自然语言编辑指令,指引编辑意图与修改范围;联合建模通过多模态编码器提取图文联合特征,借助语言引导的视觉推理能力,将模糊的自然语言映射为可执行的图像编辑语义。
2.In-context 图像生成模块(In-context Guided Image Generation),为了在编辑过程中保留原图细节与结构信息,该模块采用基于扩散模型的条件生成策略。初始状态构造将原图与随机噪声拼接,形成具有上下文感知能力的初始噪声 z,输入至DiT编辑模型中;保真引导生成通过条件约束机制,模型能够在高保真的基础上执行局部或整体编辑,同时保持视觉连贯性;Context-aware Diffusion模型不仅参考原图,还融合图文语义,对编辑区域进行精准建模,确保输出结果符合用户期望。
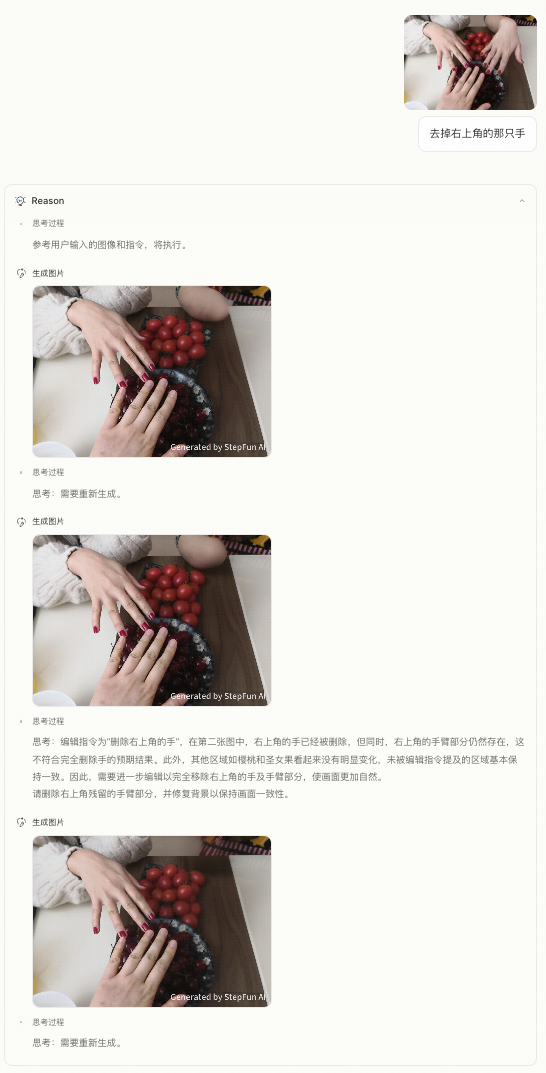
- 推理(Think):理解图像与文本指令之间的关系,定位目标区域/属性,推理编辑意图。
- 编辑(Act):执行图像级别的修改操作,满足用户需求的同时保持图像自然性与一致性。
- 反思(Reflect):评估编辑结果是否达成目标,并在必要时进行自我修正或重编辑。 针对上述目标,需构建图像–文本–目标图的三元组数据,以覆盖多样化的编辑目标、物体类别、风格变换及构图调整场景。数据可来源于三类方式:(1)自动构建:通过脚本式修改生成大规模基础编辑对;(2)人工标注:基于图像编辑器收集真实操作轨迹与用户指令;(3)人机共建:通过模型生成初稿+人工反馈构造多轮编辑链。多样化的编辑类型、任务目标和多轮交互数据,有助于提升模型的泛化推理与复杂场景适应能力。 整体训练过程采用分阶段优化策略:(1)预训练阶段,训练图文理解模块建立多模态语义对齐能力;(2)主干阶段,采用条件扩散模型或 inpainting 网络完成图像的高保真编辑;(3)优化阶段,引入反思模块,对生成结果进行质量评估与自我修正,实现“生成–评估–再生成”的迭代过程。通过上述训练流程,模型不仅能执行编辑任务,更具备自主理解任务意图、做出合理编辑决策并优化输出结果的“图像中思考”能力。
三、模型表现结果
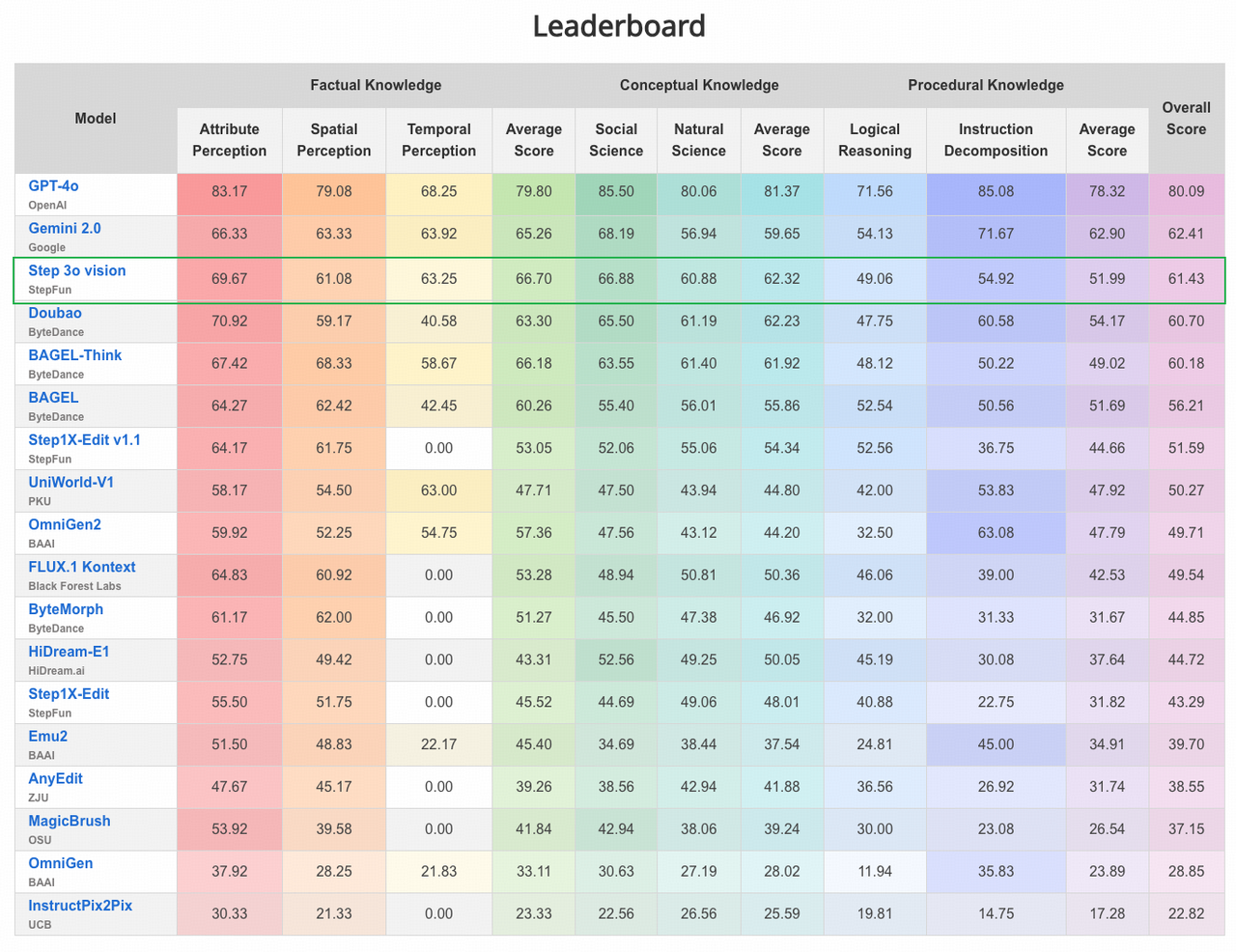
我们将训练完成的深度图像编辑模型应用于高难度的推理编辑评测数据集——KRIS-Bench,以系统性地评估模型在复杂编辑任务中的知识理解与推理能力。KRIS-Bench 是一个专为知识驱动图像编辑设计的基准测试集,涵盖了三种关键的知识类型:事实型(Factual)、概念型(Conceptual)以及程序型(Procedural),分别对应模型对世界事实、知识概念以及操作流程等不同层次知识的掌握情况。 该基准测试集广泛用于评测当前最先进的多模态模型在编辑任务中融合语言与视觉知识进行推理与操作的能力。在 KRIS-Bench 的正式评测中,我们的模型 Step 3o Vision 表现突出,总分排名第三,仅次于 GPT-4o 和 Gemini 2.0,在多个子任务中展现出强大的指令理解与知识编辑能力。这一结果表明 Step 3o Vision 在处理复杂、高阶知识编辑任务时,已经具备与顶尖通用多模态模型相当的推理表现。
四、案例展示
案例一,生物成长形态推测:模型识别了图中的内容是一只蝌蚪并推理出生物长大后是一只青蛙的结果,给出了明确的推理后的指令「将图中的蝌蚪替换为一只青蛙」,展现出模型图像内容理解能力和广泛的世界知识储备。


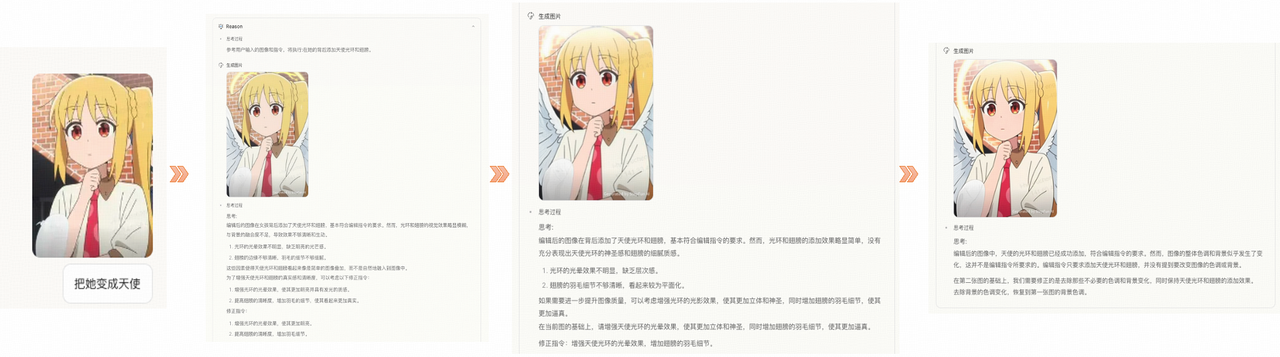
五、think with image 挑战与展望
尽管“think with image”范式为图像编辑智能化提供了新的方向,但要实现类人层次的图文联合理解与推理编辑,仍面临诸多挑战:
- 复杂语义理解能力仍有限:当前多模态模型在处理多指令、歧义语言、跨图语境等场景下仍存在理解偏差,难以精准定位用户意图,尤其在涉及空间关系、细粒度属性或组合动作时推理能力不足。
- 真实世界数据获取成本高:高质量图-文-图三元组数据获取困难,特别是多轮编辑链、模糊指令反馈等真实场景数据稀缺,影响模型的泛化与真实交互表现。
- 编辑控制精度与可解释性不足:尽管扩散模型具备强大的图像生成能力,但编辑区域可控性、细节保持性以及输出行为的可解释性仍有待提升,难以在高精度应用场景中部署。
- 编辑行为与审美风格共建模型:未来模型不仅能正确“做出修改”,还应理解编辑背后的审美逻辑与风格偏好,实现从工具化向创意协同体的转变,服务更高层次的设计需求。
- 知识注入与结构化推理融合:结合外部视觉知识库或图结构信息,引导模型显式推理图像中对象、关系与动作,提升复杂任务的决策能力和语义理解深度。