I. Challenge & Motivation
Current LLM-based speech conversational systems face significant challenges:
- High-latency and error compounding through long pipeline: Traditional ASR + LLM + TTS pipelines need ineffective and complex deployment, causing high-latency and error compounding.
- Lacking paralinguistic information modeling: Existing solutions still focus on semantic content and struggle to capture paralinguistic information including intonation, emotion, and vocal states.
- Lacking access to real-world knowledge: Current LALMs lack access to real-world textual and acoustic knowledge, leading to hallucination and few choices of timbres and speaking styles.
Step-Audio 2 resolves these through three innovations:
- Genuine end-to-end architecture: Direct processing raw audio and generating discrete audio tokens, reducing latency while simplifying deployment
- Audio understanding with reinforcement learning: Enabling effective and precise paralinguistic and non-vocal information comprehension
- Multimodal retrieval augmented generation: Leverages web search to eliminate hallucinations and audio search to enable diverse timbre switching
Demos
StepFun AI, your intelligent speech assistant.
Comprehensive Listening: Vocal Sound Understanding
Voice Analysis: Paralinguistic Information Understanding
Cognitive Expertise: Learning & Computation
Multilingual Mastery: English & Chinese Dialect
Colorful Voice: Diverse Timbres
Creative Expression: Narrative Generation
Empathic Companion: Emotion-aware Reasoning
II. Technical Advantages: Innovations and Breakthroughs
Compared to existing solutions, Step-Audio 2 introduces:
2.1 Architecture Innovation
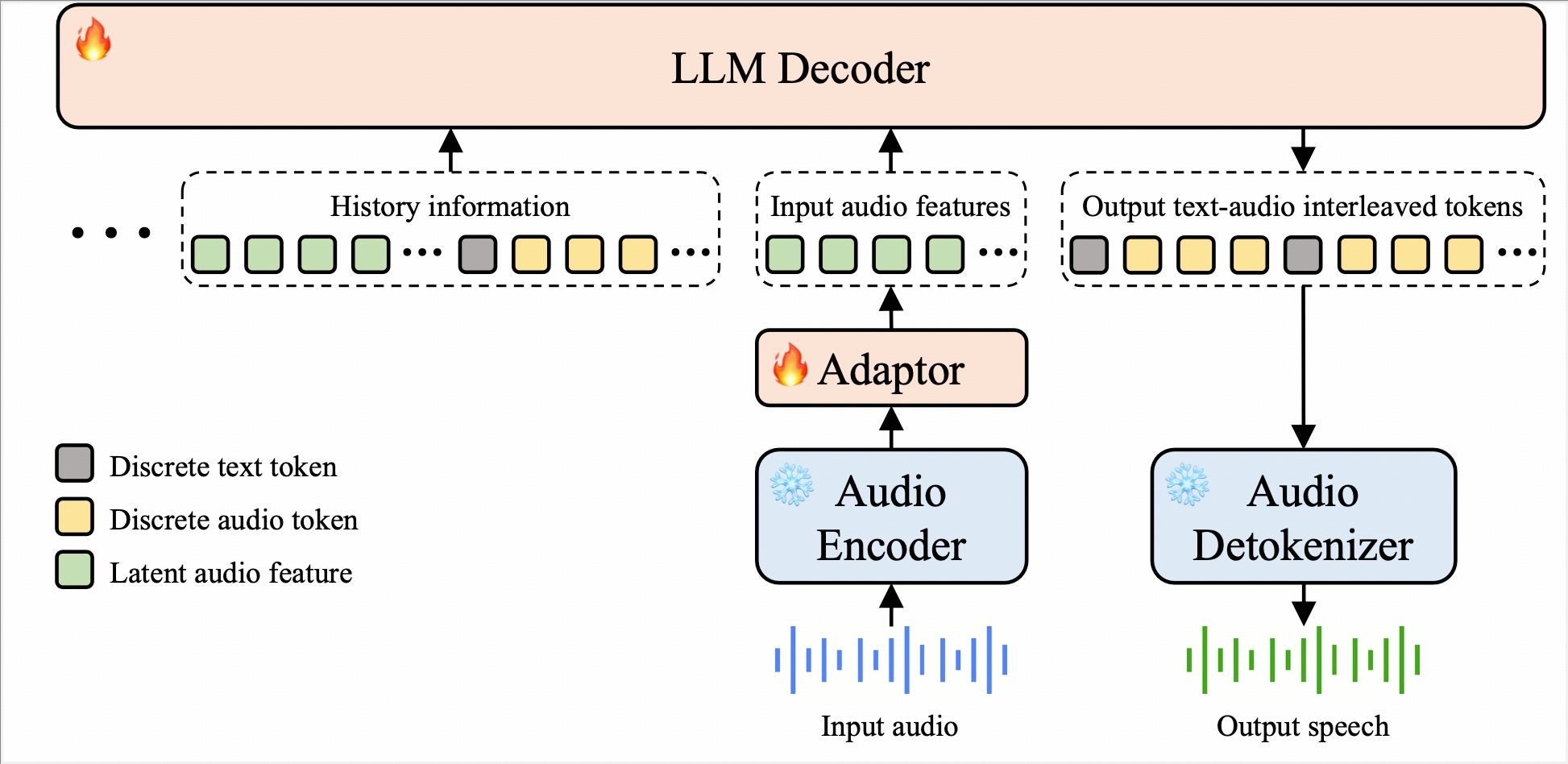
- End-to-end modeling
⇨ Eliminates traditional ASR + LLM + TTS pipelines
⇨ Reduces latency and simplifies architecture - Continuous input, discrete output paradigm
⇨ Processes raw waveforms to prevent feature loss
⇨ Ensures synthesis stability via discrete acoustic tokens - Interleaved modality alignment
⇨ Implements fixed-ratio text-speech token interleaving
⇨ Ensures tight modality alignment while maximizing cognitiveness
2.2 Data Engineering
- Million hours of acoustic corpus
⇨ Training spans languages, scenarios, and device environments - Expressive & emotional speech conversation synthesis pipeline
2.3 Highlights
- Intelligent speech conversation
⇨ Industry-leading speech conversation experience:- #1 globally in Chinese and #1 domestically in English speech conversation benchmark (URO-Bench)
- Audio understanding and reasoning
⇨ Industry-leading audio comprehension:- 76.55% accuracy on 11 paralinguistic features (StepEval-Audio-Paralinguistic)
- 77.4% on MMAU benchmark, surpassing GPT-4o-Audio, Audio Flamingo 3 and Omni-R1
- Diverse timbres
⇨ Real-time timbre switching triggered by open set natural language
III. Experience Step-Audio 2
You can chat with Step-Audio 2 in the latest Chinese version of StepFun App! Open the app and select the microphone icon for live chat:
IV. Benchmark Performance
1. Public Leaderboards
-
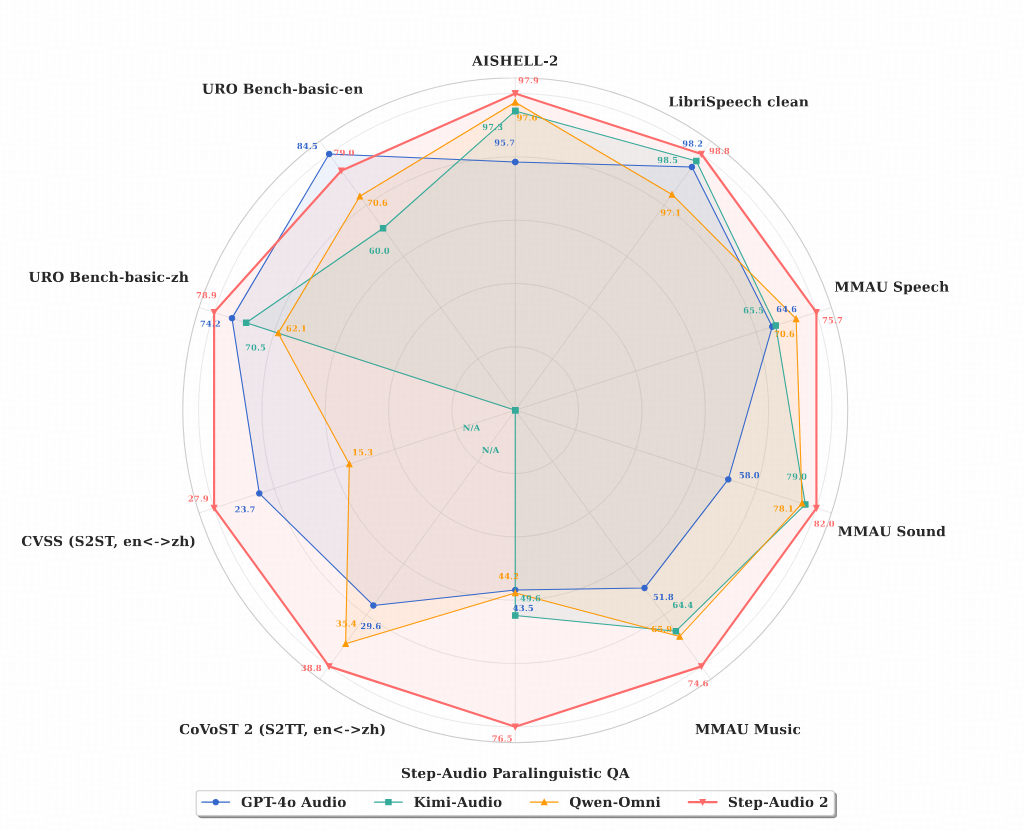
SOTA on multiple ASR benchmarks:
- English: #1 globally on Common Voice/LibriSpeech, #1 domestically on Fleurs-EN
- Chinese: #1 globally on AISHELL-2/WenetSpeech, #1 globally on KeSpeech (Chinese dialects and accents), #1 domestically on Fleurs-zh
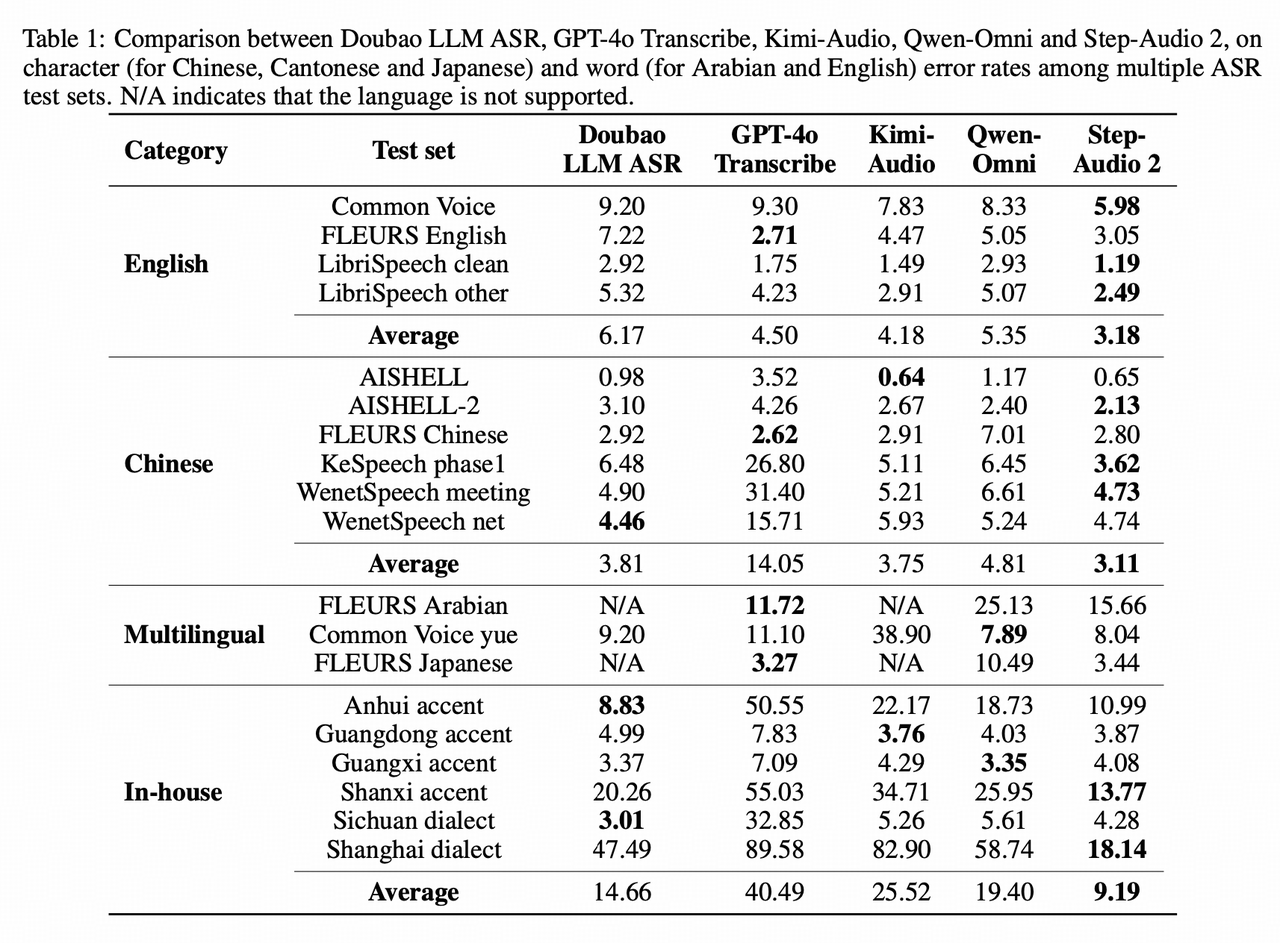
-
MMAU: #1 globally, outperforming GPT-4o Audio and specialized audio understanding models including Audio Flamingo 3 and Omni-R1
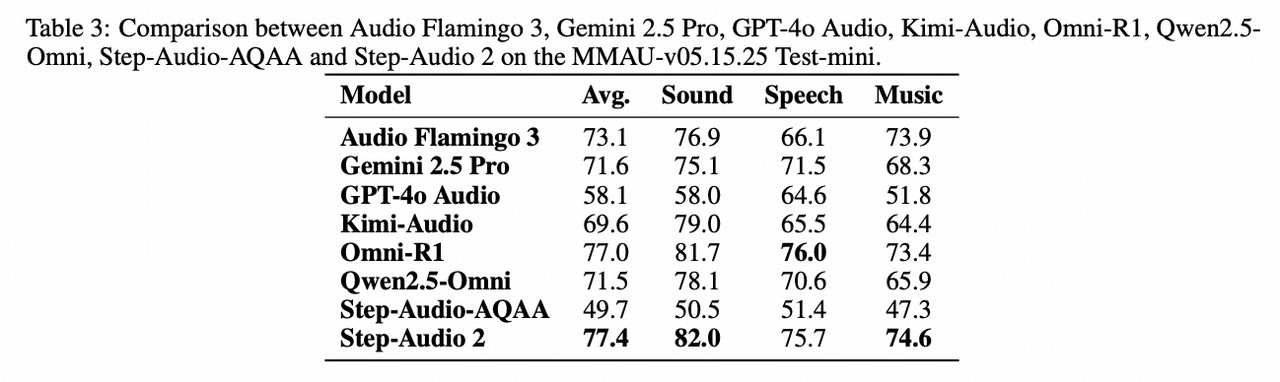
-
URO-Bench: #1 globally for Chinese, #1 domestically for English
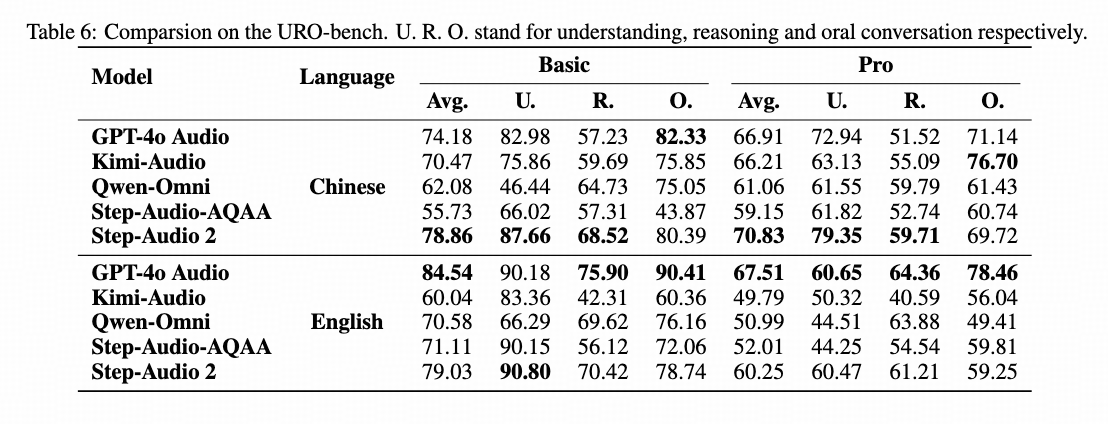
2. Self-built Benchmarks
-
StepEval-Audio-Paralinguistic: The first paralinguistic comprehension benchmark in the industry, ranked #1 globally
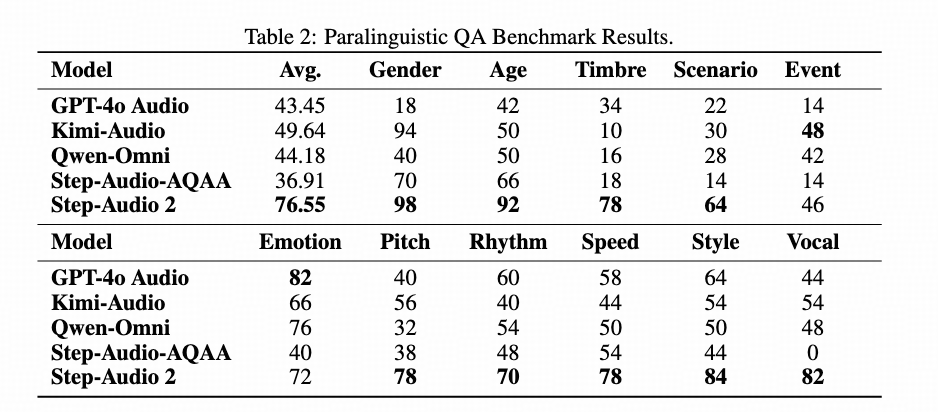
-
StepEval-Audio-Toolcall: The first voice-enabled toolcall benchmark for LALM, on par with textual LLM